8 Test d’hypothèses
Si l’on essaie d’estimer le rendement \(\mu\) d’un actif financier, on cherche implicitement à savoir si l’on va investir ou pas. Cette décision dépendra de notre estimation : pour faire simple, on peut considérer que si nous estimons que le rendement est positif (\(\hat{\mu}>0\)), alors il faut investir. Sinon, on n’investira pas.
Les tests d’hypothèses visent à formaliser cela. Faire une hypothèse dans un modèle statistique \((\mathcal{X}, \mathscr{F}, (P_\theta)_{\theta \in \Theta})\), c’est supposer que \(\theta\) appartient à une certaine région de \(H_0 \subset \Theta\). Les tests visent à construire des procédures pour tester une hypothèse nulle, que l’on notera \(H_0\), contre une hypothèse alternative, notée \(H_1\).
Dans le cadre ci-dessus, on peut se placer dans un modèle où les rendements sont \(\mathscr{N}(\mu, \sigma^2)\). On veut tester l’hypothèse nulle \(H_0 : \mu \in ]-\infty, 0]\) contre l’hypothèse alternative \(H_1 : \mu \in ]0,+\infty[\).
Définition 8.1 Un test est un événement qui, s’il survient, nous incite à rejeter l’hypothèse nulle. Cet événement sera noté \(\mathsf{rejeter}\) et son complémentaire sera noté \(\mathsf{accepter}\).
L’erreur de première espèce est la probabilité de rejeter l’hypothèse nulle à tort : \(\alpha = \sup_{\theta \in H_0}P_\theta(\mathsf{rejeter})\). Le niveau d’un test est \(1-\alpha\). C’est la probabilité d’accepter l’hypothèse nulle à raison.
L’erreur de seconde espèce est la probabilité de ne pas rejeter l’hypothèse nulle, à tort : \(\beta = \sup_{\theta \in H_1}P_\theta(\mathsf{accepter})\). La puissance d’un test est \(1-\beta\). C’est la probabilité de « détecter » l’hypothèse alternative à raison.
L’affinité d’un test est la somme des erreurs de première et seconde espèce. On parle aussi de l’erreur totale.
Par « événement », on veut bien dire « un élément de \(\mathscr{F}\) », c’est-à-dire qui n’est déterminé que par les observations et pas par \(\theta\). Formellement on écrit souvent qu’un test est une statistique, disons \(T\), à valeurs dans \(\{0,1\}\). L’événement \(\{T=1\}\) est \(\mathsf{rejeter}\), l’événement \(\{T=0\}\) est \(\mathsf{accepter}\).
Un des grands objectifs de la statistique mathématique est de construire des familles de tests qui, pour un niveau de confiance \(1-\alpha\) fixé, ont la plus grande puissance possible ; autrement dit, trouver un événement hautement improbable sous l’hypothèse nulle, et hautement probable sous l’hypothèse alternative.
Comme on verra dans les exemples, le rôle des deux hypothèses n’est pas interchangeable. Maximiser le niveau et la puissance ne reviennent pas au même. Le choix des hypothèses \(H_0\) et \(H_1\) n’est pas anodin : l’hypothèse \(H_0\) est une hypothèse que l’on cherche implicitement à réfuter.
- Si \(\theta \in H_0\) quel qu’il soit, les probablités pour qu’un certain événement \(\mathsf{rejeter}\) sont infimes – disons, 1%.
- Si cet événement arrive, par contraposée, on est amenés à rejeter l’hypothèse selon laquelle \(\theta\) est dans \(H_0\).
C’est pour cela que les tests sont une forme de logique statistique. Le raisonnement de base une contraposée : en logique, \(A \Rightarrow B\) est équivalent à \(\neg B \Rightarrow \neg A\). En statistiques, on pourrait écrire \(\theta \in H_0 \Rightarrow \mathsf{accepter}\) (avec grande probabilité), donc \(\mathsf{rejeter}\Rightarrow \theta \notin H_0\) (probablement).
8.1 Exemples de tests gaussiens
On se place dans un modèle où \(X_1, \dotsc, X_n\) sont des gaussiennes \(N(\mu, \sigma^2)\). Nous avons déjà vu plusieurs fois que \(\bar{X}_n \sim N(\mu, \sigma^2/n)\).
Construction du test
On cherche à réfuter l’hypothèse selon laquelle ces variables aléatoires sont centrées ; autrement dit, on posera \(H_0 = \{\mu=0\}\). Sous cette hypothèse, nos variables aléatoires sont donc des variables \(N(0,\sigma^2)\).
Supposons dans un premier temps que \(\sigma^2\) est connue. Sous \(H_0\), on a donc \[ \frac{\sqrt{n}\bar{X}_n}{\sigma} \sim N(0,1)\] et par conséquent, \(P_0(|\bar{X}_n| < z_{1-\alpha} \sigma / \sqrt{n}) = 1-\alpha\). Autrement dit, sous l’hypothèse \(\mu = 0\), on devrait observer l’événement \[ \bar{X}_n \in \left[ \pm \frac{z_{1-\alpha} \sigma}{\sqrt{n}}\right]\] avec probabilité élevée \(1-\alpha\). Si cet événement n’est pas observé, il est alors très douteux que \(\mu\) soit effectivement égal à zéro ! On pose donc \[ \mathsf{rejeter}_\alpha = \{|\bar{X}_n | > z_{1-\alpha} \sigma / \sqrt{n}\}.\] Le niveau de ce test est bien \(1-\alpha\) : nous l’avons construit pour cela.
Supposons maintenant que \(\sigma\) n’est pas connue. En l’estimant via \(\hat{\sigma}_n\), nous savons que (toujours sous l’hypothèse selon laquelle \(\mu=0\)) \[ \frac{\sqrt{n}\bar{X}_n}{\hat{\sigma}_n} \sim \mathscr{T}(n-1).\] On reproduit alors le raisonnement ci-dessus : comme \(\mathbb{P}(|\bar{X}_n| < t_{n-1, 1-\alpha}\hat{\sigma}_n / \sqrt{n}) = \alpha\) où \(t_{n-1,1-\alpha}\) est le quantile symétrique de \(\mathscr{T}(n-1)\), on voit que l’événement \[ \mathsf{rejeter}_\alpha = \{|\bar{X}_n| > t_{n-1,1-\alpha}\hat{\sigma}_n / \sqrt{n}\}\] est bien un test de niveau \(1-\alpha\).
Calcul de la puissance et hypothèse alternative
Nous n’avons pas encore eu besoin de spécifier une hypothèse alternative, mais nous allons en avoir besoin pour calculer la puissance du test. Pour commencer, on va supposer que, si \(\mu\) n’est pas nulle, alors elle ne peut être égale qu’à 1. Autrement dit, \(H_1 = \{1\}\). Ce genre d’hypothèse alternative ne peut évidemment avoir de pertinence qu’en fonction du problème réel sous-jacent !
Sous l’hypothèse alternative, donc, nous savons que \(\bar{X}_n \sim N(1, \sigma^2)\). La puissance du test est définie par \(1-\beta\) où \(\beta=P_1(\mathsf{accepter}_\alpha)\) c’est-à-dire \[\begin{align}\beta &= P_1(|\bar{X}_n|\leqslant z_{1-\alpha} \sigma / \sqrt{n}) \\ &= P_1 \left(-\frac{z_{1-\alpha} \sigma}{\sqrt{n}}\leqslant \bar{X}_n \leqslant \frac{z_{1-\alpha} \sigma}{\sqrt{n}} \right) \\ &= P_1 \left(-\frac{z_{1-\alpha} \sigma}{\sqrt{n}}-1\leqslant \bar{X}_n - 1 \leqslant \frac{z_{1-\alpha} \sigma}{\sqrt{n}} -1 \right)\\ &= \Phi(-\sqrt{n}/\sigma + z_{1-\alpha}) - \Phi(-\sqrt{n}/\sigma + z_{1-\alpha}). \end{align}\] où \(\Phi(x) = \mathbb{P}(N(0,1)\leqslant x)\). Cette expression ne peut pas plus se simplifier, mais on peut quand même la borner par \(F(-\sqrt{n}/\sigma + z_{1-\alpha})\). Lorsque \(x\) est grand, nous avons vu (Théorème 3.1) que \(F(x) < e^{-x^2}/|x|\sqrt{2\pi}\). Ainsi, l’erreur de première espèce est bornée par \(O(e^{-n/\sigma^2/2} / \sqrt{n})\). Cela tend extrêmement vite vers 0 ; en fait, dès que \(n\) est plus grand que 10 et \(\sigma=1\), cette erreur est inférieure à 0.1%, donc dans ce cas le test aura une puissance supérieure à \(99.9\%\).
Que se serait-il passé si notre hypothèse alternative n’avait pas été \(\mu=1\) mais \(\mu = m\) pour n’importe quel \(m\neq 0\) ? Dans ce cas, on aurait eu \(H_1 = \mathbb{R}\setminus \{0\}\). L’erreur de première espèce aurait alors été \(\beta = \sup_{m\neq 0}\beta_m\) où \[ \beta_m = P_m(\mathsf{accepter}_\alpha).\] On revoyant les calculs ci-dessus, on voit que \[\beta_m = \Phi(-m\sqrt{n}/\sigma + z_{1-\alpha}) - \Phi(-m\sqrt{n}/\sigma + z_{1-\alpha}).\] En particulier, \[\lim_{m\to 0}\beta_m =\Phi(-z_{1-\alpha}) - \Phi(-z_{1-\alpha}) = 1-\alpha\] par continuité de \(\Phi\) et par définition de \(z_{1-\alpha}\). Ainsi, \(1-\beta = \alpha\) : pour cette seconde hypothèse alternative, la puissance de notre test… est extrêmement faible.
Cela vient du fait que notre hypothèse alternative contient des situations quasiment indiscernables de notre hypothèse nulle. Par exemple, il est quasiment impossible de distinguer \(\mu = 0\) de \(\mu = 10^{-100}\) par exemple. Cet exemple illustre la dissymétrie entre \(H_0\) et \(H_1\).
8.2 La notion de \(p\)-valeur
La construction d’un test dépend du niveau de risque \(\alpha\). Si le niveau de risque acceptable est de plus en petit, alors l’événement \(\mathsf{rejeter}_\alpha\) devrait être de moins en moins probable. D’ailleurs, \(\mathsf{rejeter}_0 = \varnothing\) et \(\mathsf{accepter}_0 = \Omega\) : si l’on ne tolère aucun niveau de risque de première espèce, c’est qu’on ne veut pas rejeter l’hypothèse nulle.
Très souvent, si \(\alpha<\beta\), on a même \[\mathsf{rejeter}_\alpha \subset \mathsf{rejeter}_\beta. \]
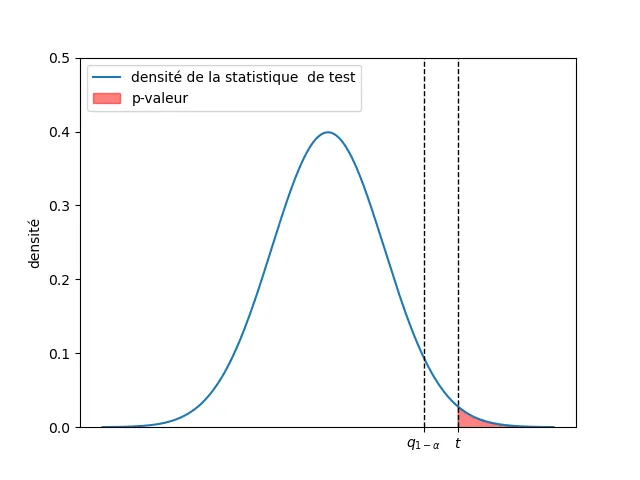
Définition 8.2 La \(p\)-valeur d’une famille croissante de tests est le plus petit niveau de risque qui nous amène à rejeter l’hypothèse nulle compte tenu des observations. Formellement, \[ p_\star = \inf\{\alpha>0 : \mathsf{rejeter}_\alpha\} = \sup\{\alpha>0 : \mathsf{accepter}_\alpha\}.\]
La \(p\)-valeur dépend des observations. C’est une observation cruciale : la \(p\)-valeur n’est pas une propriété intrinsèque d’un test. Sur deux ensembles différents d’observations, la \(p\)-valeur ne sera pas la même en général.
Calcul de \(p\)-valeur. Dans de nombreux tests, la construction d’un test se fonde sur une statistique, disons \(S\), qui sous l’hypothèse nulle suit une loi particulière (par exemple, \(\sqrt{n}\bar{X}_n / \hat{\sigma}_n \sim \mathscr{T}(n-1)\) sous l’hypothèse \(X_i \sim N(\mu,\sigma^2)\) avec \(\mu=0\) dans le cas d’un test de Student). Si le test est de la forme \(S < q_{1-\alpha}\), ce qui équivaut à \(F(S)<1-\alpha\). La \(p\)-valeur est donnée par \[p_\star = \sup\{\alpha > 0 : S < q_{1-\alpha}\} = \sup\{\alpha : F(S)<1-\alpha\} = 1 - F(S).\]